
Kafka was originally develop at LinkedIn and was subsequently open sourced to the Apache software foundation in 2011. Kafka is now widely used across enterprises including in companies such as Apple, eBay, Pintrest, Uber, Netflix, Walmart and many more.
Kafka interview questions fall into three main categories
1. Questions on Kafka architecture - These are interview questions on Kafka brokers, Kafka topics, Partitions, Offsets, Producers, Consumers, Consumer groups, data replication, how to estimate number of partitions, how to estimate number of producers and consumers etc.
2. Questions on Kafka framework APIs and libraries - These are interview questions on programming Kafka consumers, Kafka producers etc. using Kafka framework APIs and libraries.
3. Questions on real-time applications of Kafka - These are questions on how you applied Kafka in your projects, how Kafka can be used for live streaming use cases, how Kafka can be used in messaging use cases, how Kafka can be used as a storage system, how to estimate number of partitions, how to define the partition key, etc.
Below are some frequently asked Kafka interview questions in these categories.
What is Apache Kafka?
Apache Kafka is a distributed streaming platform that provides the following key capabilities.
Messaging - Kafka provides the concept of Topics, which are streams of data records. Applications can produce data streams to topics and applications can consume data streams from topics. Hence, similar to a traditional JMS messaging system, Kafka can act as a messaging system between applications.
Storage - Kafka by default stores streams of data in a distributed, replicated and fault-tolerant cluster. Data written to Kafka is written to disk and replicated across servers in the Kafka cluster for fault-tolerance. Kafka allows consumers to read from specific location on Kafka topics. This makes Kafka a good storage and distributed file system.
Processing - Apache Kafka provides the Kafka Streams API, which enables processing and transforming live data streams. Applications can use Kafka streams API to read live data streams from input topics, process and transform this data, and produce a continuous stream of transformed data to output Kafka topics.
How does Apache Kafka improve traditional architectures?
Traditional architectures usually start simple with a few systems, with point-to-point data exchange integrations between them, and a data lake or data warehouse to which data is sourced through ETL processes.
But as the number of systems grow, the number of these point-to-point integrations increase, leading to brittleness of the architecture - due to multiple data exchange protocols, multiple data formats, and multiple failure points.
Kafka is a distributed messaging system, where multiple systems can post messages to and consume messages from. So instead of the point-to-point data exchange integrations between systems in the traditional architecture, data can be exchanged globally across systems using Kafka. This leads to a stable, and scalable architecture - with minimum protocols, minimum data exchange formats, and fewer failure points.
What are some use cases where Kafka can be used?
Following are some of the key use cases where Kafka can be used.
1. Messaging - Kafka can be used in distributed messaging systems, instead of message brokers such as IBM MQ, ActiveMQ, or RabbitMQ.
2. Log Aggregation - Kafka can be used to aggregate logs from different servers and put in a central location. This is comparable to other log-centric systems like Scribe and Flume.
3. Stream processing - Kafka can be used for data pipelines where data is processed in multiple stages. Kafka streams API facilitates this data streaming process.
Event based architectures - Kafka can be used in event based architectures, where events are tracked and acted upon as time-ordered sequence of events.
Commit log - Kafka can be used as an external commit-log for nodes of a distributed system. This is comparable to Apache Bookkeeper.
What are the key components of Kafka?
Kafka consists of the following key components.
1. Kafka Cluster - Kafka cluster contains one or more Kafka brokers (servers) and balances the load across these brokers.
2. Kafka Broker - Kafka broker contains one or more Kafka topics. Kafka brokers are stateless and can handle TBs of messages and, thousands of reads and writes without impacting performance.
3. Kafka Topics - Kafka topics are categories or feeds to which streams of messages are published to. Every topic has an associated log on disk where the message streams are stored.
4. Kafka Partitions - A Kafka topic can be split into multiple partitions. Kafka partitions enable the scaling of topics to multiple servers. Kafka partitions also enable parallel consumption of messages from a topic
5. Kafka Offsets - Messages in Kafka partitions are assigned sequential id number called the offset. The offset identifies each record location within the partition. Messages can be retrieved from a partition based on its offset.
6. Kafka Producers - Kafka producers are client applications or programs that post messages to a Kafka topic.
7. Kafka Consumers - Kafka consumers are client applications or programs that read messages from a Kafka topic.
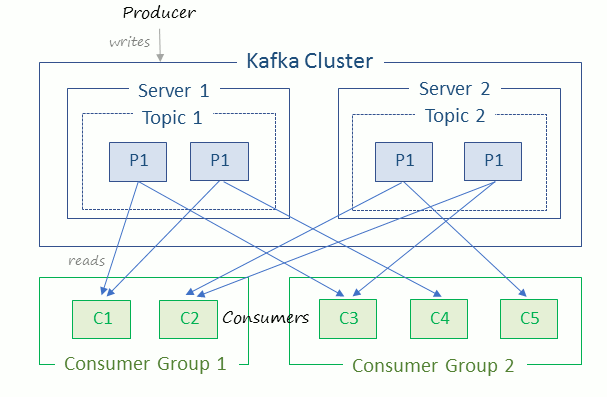
What are Kafka Topics?
Kafka Topics are categories or feeds to which data streams or data records are published to. Kafka producers publish data records to the Kafka topics and Kafka consumers consume the data records from the Kafka topics.
What is the retention policy for Kafka records in a Kafka cluster?
Kafka cluster retains all data records using a configurable retention period. The data records are retained even if they have been consumed by the consumers. For example, if the retention period is set as one week, then the data records are stored for one week after their creation before they are deleted. So consumers can access this data for one week after its creation.
What is replication factor?
Replication factor specifies the number of copies that each partition of a topic will have.
A replication factor of 2 will create 2 copies (replicas) of each partition. A replication factor of 3 will create 3 copies (replicas) of each partition. One of the replicas will be the leader, the remaining will be the followers.
You define the replication factor when you create the topic.
How are Kafka Topic partitions distributed in a Kafka cluster?
Partitions of the Kafka Topic logs are distributed over multiple servers in the Kafka cluster. Each partition is replicated across a configurable number of servers for fault tolerance.
Every partition has one server that acts as the 'leader' and zero or more servers that act as 'followers'. The leader handles the reads and writes to a partition, and the followers passively replicate the data from the leader.
If the leader fails, then one of the followers automatically take the role as the 'leader'.
What is an in-sync replica (ISR)?
An in-sync replica is a server that has the latest messages for a given partition. A leader is always an in-sync replica since it always has the latest messages. A follower replica is an in-sync replica only if it is up-to-date with the latest messages for that partition.
What is the significance of acks setting on a Kafka producer?
The acks (Acknowledgments) setting on a producer specifies the number of brokers that the messages must be committed to, for the producer to consider the write as successful.
There are three values for acks - 0, 1, and all
acks=0 - Producer considers the write to be successful immediately after sending the message - it does not wait for response from the broker
acks=1 - Producer considers the write to be successful when the message is committed to the leader
acks=all - Producer considers the write to be successful only after the message is committed to all the in-sync replicas.
What is the significance of min.insync.replicas setting on a Kafka broker?
The min.insync.replicas setting on the Kafka broker specifies the minimum number of in-sync replicas that must exist for the broker to accept and process ack=all requests. If the number of in-sync replicas are less than what is specified by the min.insync.replicas property then all the ack=all requests will be rejected by the broker.
What is the difference between Kafka and a traditional JMS messaging system?
Following are the key differences between Kafka and a traditional JMS messaging system.
Messaging Modes - A tradition messaging system has two messaging modes - point-to-point and publish-subscribe. In point-to-point messaging each message is send to a single consumer. In publish-subscribe messaging each message is broadcast to multiple consumers. Kafka combines these two modes. Similar to point-to-point messaging, Kafka topics can be consumed by specific processes (members of a consumer group). Similar to publish-subscribe messaging, Kafka topics can be broadcast to multiple consumer groups.
Data Retention - In traditional messaging systems, the message is deleted once it is consumed by the consumers. In Kafka the messages are retained based on a configurable retention period.
Order - In traditional messaging systems, messages are maintained in the order that they are put into the queue. Kafka maintains the order, but messages can be consumed from any position by specifying the sequence.
How is Kafka used as a storage system?
Kafka has the following data storage capabilities which makes it a good distributed data storage system.
Replication - Data written to Kafka topics are by design partitioned and replicated across servers for fault-tolerance.
Guaranteed - Kafka sends acknowledgment to Kafka producers after data is fully replicated across all the servers, hence guaranteeing that the data is persisted to the servers.
Scalability - The way Kafka uses disk structures enables them to scale well. Kafka performs the same irrespective of the size of the persistent data on the server.
Flexible reads - Kafka enables different consumers to read from different positions on the Kafka topics, hence making Kafka a high-performance, low-latency distributed file system.
How is Kafka used as a stream processing?
Kafka can be used to consume continuous streams of live data from input Kafka topics, perform processing on this live data, and then output the continuous stream of processed data to output Kafka topics.
For performing complex transformations on the live data, Kafka provides a fully integrated Streams API.
What is the role of Zookeeper in Apache Kafka framework?
Zookeeper performs four important functions in Kafka
1. Manages cluster memberships - Zookeeper maintains, and keep track of the status, of all the brokers that are a part of the cluster.
2. Manages configuration of topics - Zookeeper maintains and manages the configuration of topics. It maintains the list of existing topics, keeps track of the number of partitions for each topic, maintains and keeps track of the number and location of replicas, keeps track of any overrides to the configurations, etc.
3. Elects the leader broker - Zookeeper elects which Kafka broker will act as the leader for a partition. If a leader broker goes down, it will elect another broker to act as the leader.
4. Manages the service discovery of brokers - Each broker knows about all the other brokers in the cluster. If a broker comes down, or if a new broker is added. Zookeeper communicates this to each broker in the cluster.
How do you create a topic using the Kafka command line client?
You can create a topic using Kafka command line client using the script kafka-topics.sh with the --create option using parameters for replication factor, number of partitions, and the topic name.
Below code create a topic named 'test_topic' with a replication factor of 3 and 1 partition.
/** create topic */
> bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 3 --partitions 1 --topic test_topic
How do you send messages to a Kafka topic using Kafka command line client?
Kafka comes with a command line client and a producer script kafka-console-producer.sh that can be used to take messages from standard input on console and post them as messages to a Kafka queue.
> bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test-topic
>Test Message 1
>Test Message 2
How do you consume messages from a Kafka topic and output the messages to console using Kafka command line client?
Kafka comes with a command line client and a consumer script kafka-console-producer.sh that can be used to consume messages from a Kafka topic and output them to the standard console.
> bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test-topic --from-beginning
Test Message 1
Test Message 2
What are the core APIs provided in Kafka platform?
Kafka provides the following core APIs
Producer API - An application uses the Kafka producer API to publish a stream of records to one or more Kafka topics.
Consumer API - An application uses the Kafka consumer API to subscribe to one or more Kafka topics and consume streams of records.
Streams API - An application uses the Kafka Streams API to consume input streams from one or more Kafka topics, process and transform the input data, and produce output streams to one or more Kafka topics.
Connect API - An application uses the Kafka connect API to create producers and consumers that connect Kafka topics to existing applications or data systems.
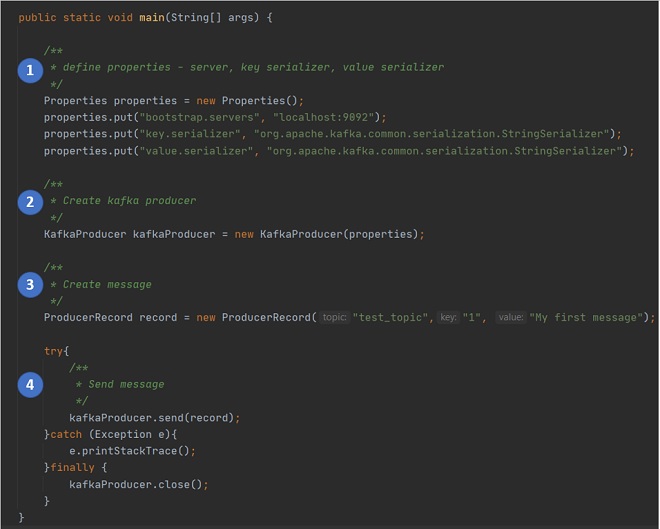
What are the keys steps in a Java program using Kafka Producer API?
Following are the key steps in a Java program using Kafka Producer API.
1. Define the properties required for the Kafka Producer - the kafka broker to connect to, the key serializer type, the value serializer type
2. Create a new instance of KafkaProducer class, passing in the properties created in step 1.
3. Create a new instance of ProducerRecord, passing in the topic name to connect to, the key, and the message.
4. Send message by calling the method send() on the KafkaProducer instance, passing the ProducerRecord instance containing the message to be send.
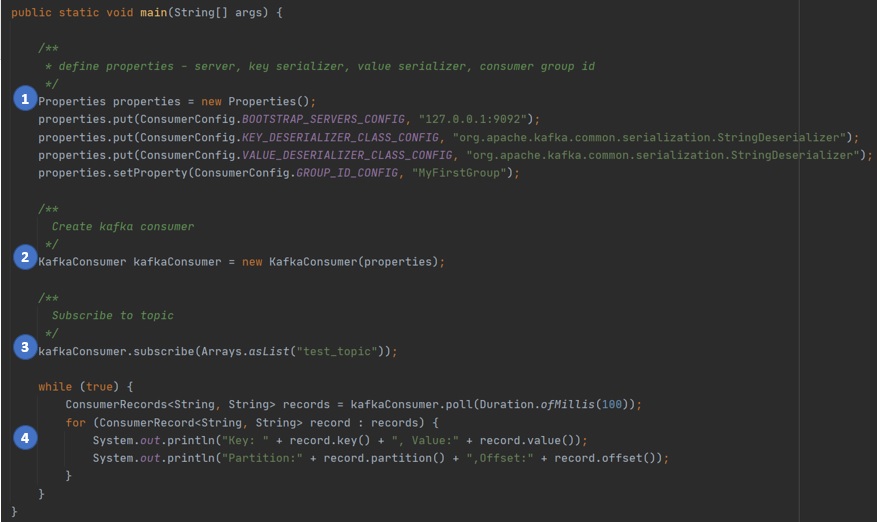
What are the keys steps in a Java program using Kafka Consumer API?
Following are the key steps in a Java program using Kafka Consumer API.
1. Define the properties required for the Kafka Consumer - the kafka broker to connect to, the key serializer type, the value serializer type, and the consumer group.
2. Create a new instance of KafkaConsumer class, passing in the properties created in step 1.
3. Subscribe to the topic to consume messages from, by calling the subscribe() method on the KafkaConsumer instance.
4. Listen to the kafka topic for new messages by calling the method poll() on KafkaConsumer instance, handling messages as instances of ConsumerRecord instances.
What security features does Kafka provide?
Kafka provides the following security features.
1. Authentication of connections from clients (producers and consumers) to brokers, using SASL mechanisms.
2. Authentication of connections from brokers to ZooKeeper.
3. SSL Encryption of data transferred between clients and brokers, brokers and ZooKeeper, and between brokers.
4. Authorization of read and write operations by clients.
5. Pluggable authorization, with the ability to integrate with external authorization services.
What is Kafka Connect?
Kafka Connect is a tool to stream data between Kafka and other systems scalably and reliably. Kafka Connect defines a common framework for Kafka connectors, can be deployed in distributed or standalone modes, and is ideal for bridging streaming and batch data systems.
What is Kafka Streams?
Kafka streams is a client library for processing input data from input Kafka clusters, transforming the data, and sending the transformed data to output Kafka clusters.
What happens if a Kafka producer posts a message to a topic that does not exist?
If a Kafka producer posts a message to a topic that does not exist, then Kafka platform creates that topic, with a default of 1 partition and 1 replication factor.
A warning is returned back by the producer saying that the topic does not exists, but the topic is created and the message is put into the topic, so the message is not lost.
Can you create a Kafka topic with replication factor greater than the number of brokers in the Kafka cluster?
No, you cannot create a Kafka topic with a replication factor greater than the number of brokers in the Kafka cluster.
For example, if you only have 3 brokers in the cluster and you try to create a topic with a replication factor of 5, then you would see an error like..
Error while executing topic command : replication factor: 5 larger than available brokers: 3
How do you setup a multi-broker Kafka cluster?
To setup a multi-broker Kafka cluster you have to do the following 3 tasks.
1. Create a server.properties file for each of the servers you want in the cluster. At a minimum, you have to change the server id, port and log location for each of the property files.
2. Start the zookeeper server.
3. Start the servers in the cluster one by one using the property file of each server.
/** create separate property file for each server */
/** config/server-1.properties*/
broker.id=1
listeners=PLAINTEXT://:9093
log.dirs=/tmp/kafka-logs-1
/** config/server-2.properties*/
broker.id=2
listeners=PLAINTEXT://:9094
log.dirs=/tmp/kafka-logs-2
/** start zookeeper server */
> bin/zookeeper-server-start.sh config/zookeeper.properties
/** start kafka server 1*/
> bin/kafka-server-start.sh config/server-1.properties
/** start kafka server 2*/
> bin/kafka-server-start.sh config/server-2.properties

Big Data - Interview Questions
