MapReduce is a programming model for processing and generating large data sets that can be executed in parallel across a large cluster of machines. MapReduce was first designed and implemented at Google to process large amounts of web related raw data such as data on user web searches, web sites crawled etc.
What is MapReduce?
FAQKey ConceptMapReduce is a programming model for processing large datasets in parallel using multiple machines. MapReduce enables large scale data analysis and data mining using clusters of machines, taking much less time compared to other data processing methods.
Describe the programming model of MapReduce?
FAQKey ConceptMapReduce processes datasets in two phases - the Map phase and the Reduce phase. Each phase has key-value pairs as input and output. Depending on the data, the programmer can specify the types for the input and output. The programmer has to implement two functions - the map function and the reduce function, which defines how the data is processed in these two phases.
Map phase - Map phase is a data preparation phase in which the data is filtered and send to the reduce phase for further processing. The map function takes an input key-value pair and produces a set of intermediate key-value pairs. The MapReduce framework sorts and groups the data by the intermediate key before sending it as input to the Reduce phase.
Reduce phase - Reduce phase takes the output key-value pairs from the Map phase as input and does further processing on that data to compute and generate the final required output. The input key is the intermediate key that is output from the map function and value contains a list of values for that key.
What are input data splits in MapReduce?
FAQKey ConceptThe MapReduce framework splits input files into multiple pieces of fixed sizes, say 16 MB to 64 MB each. The splits are then send as input to multiple map tasks, which can be run parallelly on a cluster of machines.
What is master and worker programs in MapReduce?
FAQKey ConceptThe MapReduce framework splits the input data and starts copies of the MapReduce user program on a cluster of machines. One of the copies acts as the master program and the rest are worker programs. The master is responsible for assigning tasks to the workers. The master keeps track of the state of workers, and assigns each worker a map task or a reduce task.
What is partitioning in MapReduce?
FAQKey ConceptThe intermediate key-value pairs generated by the map task are buffered in memory and are periodically written to the local disc on which the map task runs. This data is partitioned into multiple regions on the disk, based on the hash of the key and number of reducers, by the partitioning function.
The locations of the buffered data on the local disc are send to reduce tasks, which use remote procedure calls to pull the data and process them.
What is shuffling and sorting in MapReduce?
FAQKey ConceptThe map tasks generate intermediate key-value pairs and store them on partitions on the local discs. Shuffling is the process of transferring this intermediate data generated on multiple machines to reducers. This data fetched by the reducers are sorted and grouped by the intermediate key, before the data is send as input to the reduce task.
What data is maintained by the master in MapReduce framework?
FAQKey ConceptThe master is responsible for assigning map tasks and reduce tasks to workers. For each map task and reduce task, the master stores the state of the task - idle, in-progress or completed; and the identity of the worker machine that is running the task.
The master assigns reduce tasks to workers and has to send the locations of the intermediate key-value data that the map task generates. Hence for every completed map task, the master stores the locations and sizes of the intermediate key-value data produced by the map task.
How does MapReduce tolerate node failures?
FAQKey ConceptMapReduce is resilient to machine failures. The master pings the workers periodically, and marks a worker as failed if it does not receive a response within a specific time period.
A map task or reduce task that was being processed by the failed worker is reset to idle state, so that the task is processed again by another worker.
A map task completed by the failed worker is reset to idle state, so that it is processed again by another worker. The map task has to be re-processed since it stores the intermediate output on the local disc. A reduce task completed by the failed worker need not be re-processed since the output is stored globally.
What are stragglers in MapReduce? How does MapReduce alleviate the problem of stragglers?
FAQKey ConceptA straggler is a machine in the MapReduce cluster that takes an unusually long time to complete a map or reduce task, and the MapReduce operation is usually waiting for just this last task to complete. This could arise due to different issues on the machine such as low network bandwidth, low CPU, low memory etc.
MapReduce provides a mechanism to alleviate the problem of stragglers. When a MapReduce program is close to completion, the master can be set to schedule backup executions of the in-progress tasks. The task is them masked as complete when either the primary or the backup process is complete.
What are counters in MapReduce?
FAQKey ConceptCounter is a facility provided in the MapReduce framework that can be used to count various events aggregated across the cluster machines. The counter is created in the MapReduce user program and can be incremented in the map or reduce task. The counter values from all worker machines are propagated to the master which aggregates the counter values and returns it to the user program after the MapReduce operation is complete.
What are combiner functions?
FAQKey ConceptIn a multi-node clustered environment the efficiency of MapReduce jobs is limited by the bandwidth availability on the cluster. In such environments, combiner functions minimize the data transfered between the map and reduce tasks.
The combiner function acts on the output from the map task, and minimizes the data before it is send to the Reduce task.
The combiner task is set on the Job by calling the setCombinerClass() method on the Job instance.
What is Apache Flume?
Apache Flume is an open source platform to efficiently and reliably collect, aggregate and transfer massive amounts of data from one or more sources to a centralized data source. Data sources are customizable in Flume, hence it can injest any kind of data including log data, event data, network data, social-media generated data, email messages, message queues etc.
What are the key components used in Flume data flow?
Flume flow has three main components - Source, Channel and Sink
Source: Flume source is a Flume component that consumes events and data from sources such as a web server or message queue.Flume sources are customized to handle data from specific sources. For example, an Avro Flume source is used to injest data from Avro clients and a Thrift flume source is used to injest data from Thrift clients. You can write custom Flume sources to inject custom data. For example you can write a Twitter Flume source to injest Tweets.
Channel: Flume sources injest data and store them into one or more channels.Channels are temporary stores, that keep the data until it is consumed by Flume sinks.
Sink: Flume sinks removes the data stored in channels and puts it into a central repository such as HDFS or Hive.
What is flume Agent?
A Flume agent is a JVM process that hosts the components through which events flow from an external source to either the central repository or to the next destination.Flume agent wires togeatrher the external sources, Flume sources, flume Channels, Flume sinks, and external destinations for each flume data flow. Flume agent does this through a configuration file in which it maps the sources, channels, sinks, etc. and defines the properties for each component.
How is reliability of data delivery ensured in Flume?
Flume uses a transactional approach to gaurantee the delivery of data. Events or data is removed from channels only after they have been successfully stored in the terminal reposiroty for single-hop flows, or successfully stored in the channel of next agent in the case of multi-hop flows.
How is recoverability ensured in Flume?
In Flume the events or data is staged in channels. Flume sources add events to Flume channels. Flume sinks consume events from channels and publish to terminal data stores. Channels manage recovery from failures. Flume supports different kinds of channels. In-memory channels store events in an in-memory queue, which is faster. File channels are durable which is backed by the local file system.
How do you install third-party plugins into Flume? OR Why do you need third-party plugins in Flume? OR What are the different ways you can install plugins into flume?
Flume is a plugin-based architecture. It ships with many out-of-the-box sources, channels and sinks. Many other customized components exist seperately from Flume which can be pluged into Flume and used for you applications. Or you can write your own custom components and plug them into Flume.
There are two ways to add plugins to Flume.
Add the plugin jar files to FLUME_CLASSPATH variable in the flume-env.sh file.
What do you mean by consolidation in Flume? Or How do you injest data from multiple sources into a single terminal destination?
Flume can be setup to have multiple agents process data from multiple sources and send to a single or a few intermiate destimations. Separate agents consume messages from the intermediate data source and write to a central data source.
How do you check the integrity of file channels?
Fluid platform provides a File Channel Integrity tool which verifies the integrity of individual events in the File channel and removes corrupted events.
How do you handle agent failues?
If Flume agent goes down then all flows hosted on that agent are aborted.Once the agent is restarted then flow will resume. If the channel is set up as in-memory channel then all events that are stored in the chavvels when the agent went down are lost. But chanels setup as file or other stable channels will continue to process events where it lest off.
Kafka was originally develop at LinkedIn and was subsequently open sourced to the Apache software foundation in 2011. Kafka is now widely used across enterprises including in companies such as Apple, eBay, Pintrest, Uber, Netflix, Walmart and many more.
What is Apache Kafka?
FAQApache Kafka is a distributed streaming platform that provides the following key capabilities.
Messaging - Kafka provides the concept of Topics, which are streams of data records. Applications can produce data streams to topics and applications can consume data streams from topics. Hence, similar to a traditional JMS messaging system, Kafka can act as a messaging system between applications.
Storage - Kafka by default stores streams of data in a distributed, replicated and fault-tolerant cluster. Data written to Kafka is written to disk and replicated across servers in the Kafka cluster for fault-tolerance. Kafka allows consumers to read from specific location on Kafka topics. This makes Kafka a good storage and distributed file system.
Processing - Apache Kafka provides the Kafka Streams API, which enables processing and transforming live data streams. Applications can use Kafka streams API to read live data streams from input topics, process and transform this data, and produce a continuous stream of transformed data to output Kafka topics.
How does Apache Kafka improve traditional architectures?
FAQTraditional architectures usually start simple with a few systems, with point-to-point data exchange integrations between them, and a data lake or data warehouse to which data is sourced through ETL processes.
But as the number of systems grow, the number of these point-to-point integrations increase, leading to brittleness of the architecture - due to multiple data exchange protocols, multiple data formats, and multiple failure points.
Kafka is a distributed messaging system, where multiple systems can post messages to and consume messages from. So instead of the point-to-point data exchange integrations between systems in the traditional architecture, data can be exchanged globally across systems using Kafka. This leads to a stable, and scalable architecture - with minimum protocols, minimum data exchange formats, and fewer failure points.
What are some use cases where Kafka can be used?
FAQFollowing are some of the key use cases where Kafka can be used.
1. Messaging - Kafka can be used in distributed messaging systems, instead of message brokers such as IBM MQ, ActiveMQ, or RabbitMQ.
2. Log Aggregation - Kafka can be used to aggregate logs from different servers and put in a central location. This is comparable to other log-centric systems like Scribe and Flume.
3. Stream processing - Kafka can be used for data pipelines where data is processed in multiple stages. Kafka streams API facilitates this data streaming process.
Event based architectures - Kafka can be used in event based architectures, where events are tracked and acted upon as time-ordered sequence of events.
Commit log - Kafka can be used as an external commit-log for nodes of a distributed system. This is comparable to Apache Bookkeeper.
What are the key components of Kafka?
FAQKafka consists of the following key components.
1. Kafka Cluster - Kafka cluster contains one or more Kafka brokers (servers) and balances the load across these brokers.
2. Kafka Broker - Kafka broker contains one or more Kafka topics. Kafka brokers are stateless and can handle TBs of messages and, thousands of reads and writes without impacting performance.
3. Kafka Topics - Kafka topics are categories or feeds to which streams of messages are published to. Every topic has an associated log on disk where the message streams are stored.
4. Kafka Partitions - A Kafka topic can be split into multiple partitions. Kafka partitions enable the scaling of topics to multiple servers. Kafka partitions also enable parallel consumption of messages from a topic
5. Kafka Offsets - Messages in Kafka partitions are assigned sequential id number called the offset. The offset identifies each record location within the partition. Messages can be retrieved from a partition based on its offset.
6. Kafka Producers - Kafka producers are client applications or programs that post messages to a Kafka topic.
7. Kafka Consumers - Kafka consumers are client applications or programs that read messages from a Kafka topic.
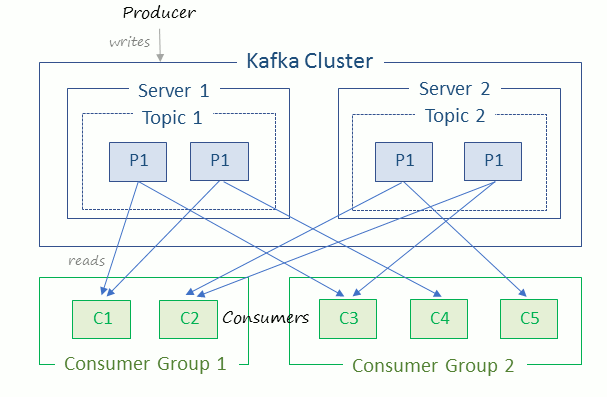
What are Kafka Topics?
FAQKafka Topics are categories or feeds to which data streams or data records are published to. Kafka producers publish data records to the Kafka topics and Kafka consumers consume the data records from the Kafka topics.
What is the retention policy for Kafka records in a Kafka cluster?
FAQKafka cluster retains all data records using a configurable retention period. The data records are retained even if they have been consumed by the consumers. For example, if the retention period is set as one week, then the data records are stored for one week after their creation before they are deleted. So consumers can access this data for one week after its creation.
What is replication factor?
FAQReplication factor specifies the number of copies that each partition of a topic will have.
A replication factor of 2 will create 2 copies (replicas) of each partition. A replication factor of 3 will create 3 copies (replicas) of each partition. One of the replicas will be the leader, the remaining will be the followers.
You define the replication factor when you create the topic.
How are Kafka Topic partitions distributed in a Kafka cluster?
FAQPartitions of the Kafka Topic logs are distributed over multiple servers in the Kafka cluster. Each partition is replicated across a configurable number of servers for fault tolerance.
Every partition has one server that acts as the 'leader' and zero or more servers that act as 'followers'. The leader handles the reads and writes to a partition, and the followers passively replicate the data from the leader.
If the leader fails, then one of the followers automatically take the role as the 'leader'.
What is an in-sync replica (ISR)?
FAQAn in-sync replica is a server that has the latest messages for a given partition. A leader is always an in-sync replica since it always has the latest messages. A follower replica is an in-sync replica only if it is up-to-date with the latest messages for that partition.
What is the significance of acks setting on a Kafka producer?
FAQThe acks (Acknowledgments) setting on a producer specifies the number of brokers that the messages must be committed to, for the producer to consider the write as successful.
There are three values for acks - 0, 1, and all
acks=0 - Producer considers the write to be successful immediately after sending the message - it does not wait for response from the broker
acks=1 - Producer considers the write to be successful when the message is committed to the leader
acks=all - Producer considers the write to be successful only after the message is committed to all the in-sync replicas.
What is the significance of min.insync.replicas setting on a Kafka broker?
FAQThe min.insync.replicas setting on the Kafka broker specifies the minimum number of in-sync replicas that must exist for the broker to accept and process ack=all requests. If the number of in-sync replicas are less than what is specified by the min.insync.replicas property then all the ack=all requests will be rejected by the broker.
What is the difference between Kafka and a traditional JMS messaging system?
FAQFollowing are the key differences between Kafka and a traditional JMS messaging system.
Messaging Modes - A tradition messaging system has two messaging modes - point-to-point and publish-subscribe. In point-to-point messaging each message is send to a single consumer. In publish-subscribe messaging each message is broadcast to multiple consumers. Kafka combines these two modes. Similar to point-to-point messaging, Kafka topics can be consumed by specific processes (members of a consumer group). Similar to publish-subscribe messaging, Kafka topics can be broadcast to multiple consumer groups.
Data Retention - In traditional messaging systems, the message is deleted once it is consumed by the consumers. In Kafka the messages are retained based on a configurable retention period.
Order - In traditional messaging systems, messages are maintained in the order that they are put into the queue. Kafka maintains the order, but messages can be consumed from any position by specifying the sequence.
How is Kafka used as a storage system?
FAQKafka has the following data storage capabilities which makes it a good distributed data storage system.
Replication - Data written to Kafka topics are by design partitioned and replicated across servers for fault-tolerance.
Guaranteed - Kafka sends acknowledgment to Kafka producers after data is fully replicated across all the servers, hence guaranteeing that the data is persisted to the servers.
Scalability - The way Kafka uses disk structures enables them to scale well. Kafka performs the same irrespective of the size of the persistent data on the server.
Flexible reads - Kafka enables different consumers to read from different positions on the Kafka topics, hence making Kafka a high-performance, low-latency distributed file system.
How is Kafka used as a stream processing?
FAQKafka can be used to consume continuous streams of live data from input Kafka topics, perform processing on this live data, and then output the continuous stream of processed data to output Kafka topics.
For performing complex transformations on the live data, Kafka provides a fully integrated Streams API.
What is the role of Zookeeper in Apache Kafka framework?
FAQZookeeper performs four important functions in Kafka
1. Manages cluster memberships - Zookeeper maintains, and keep track of the status, of all the brokers that are a part of the cluster.
2. Manages configuration of topics - Zookeeper maintains and manages the configuration of topics. It maintains the list of existing topics, keeps track of the number of partitions for each topic, maintains and keeps track of the number and location of replicas, keeps track of any overrides to the configurations, etc.
3. Elects the leader broker - Zookeeper elects which Kafka broker will act as the leader for a partition. If a leader broker goes down, it will elect another broker to act as the leader.
4. Manages the service discovery of brokers - Each broker knows about all the other brokers in the cluster. If a broker comes down, or if a new broker is added. Zookeeper communicates this to each broker in the cluster.
How do you create a topic using the Kafka command line client?
FAQYou can create a topic using Kafka command line client using the script kafka-topics.sh with the --create option using parameters for replication factor, number of partitions, and the topic name.
Below code create a topic named 'test_topic' with a replication factor of 3 and 1 partition.
/** create topic */
> bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 3 --partitions 1 --topic test_topic
How do you send messages to a Kafka topic using Kafka command line client?
FAQKafka comes with a command line client and a producer script kafka-console-producer.sh that can be used to take messages from standard input on console and post them as messages to a Kafka queue.
> bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test-topic
>Test Message 1
>Test Message 2
How do you consume messages from a Kafka topic and output the messages to console using Kafka command line client?
FAQKafka comes with a command line client and a consumer script kafka-console-producer.sh that can be used to consume messages from a Kafka topic and output them to the standard console.
> bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test-topic --from-beginning
Test Message 1
Test Message 2
What are the core APIs provided in Kafka platform?
FAQ, Key ConceptKafka provides the following core APIs
Producer API - An application uses the Kafka producer API to publish a stream of records to one or more Kafka topics.
Consumer API - An application uses the Kafka consumer API to subscribe to one or more Kafka topics and consume streams of records.
Streams API - An application uses the Kafka Streams API to consume input streams from one or more Kafka topics, process and transform the input data, and produce output streams to one or more Kafka topics.
Connect API - An application uses the Kafka connect API to create producers and consumers that connect Kafka topics to existing applications or data systems.
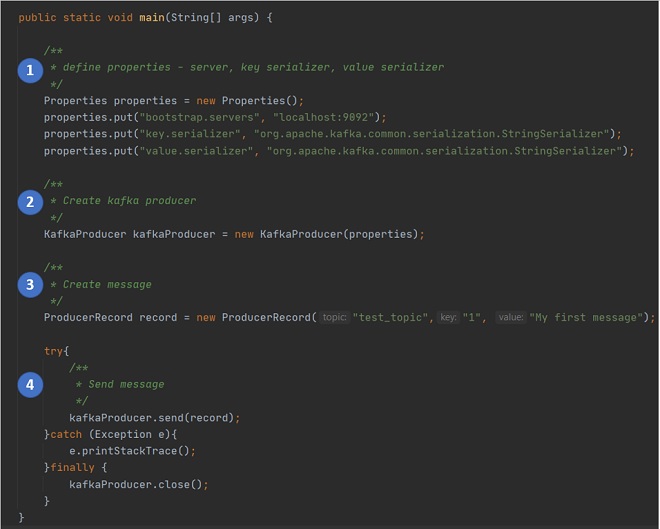
What are the keys steps in a Java program using Kafka Producer API?
Key ConceptFollowing are the key steps in a Java program using Kafka Producer API.
1. Define the properties required for the Kafka Producer - the kafka broker to connect to, the key serializer type, the value serializer type
2. Create a new instance of KafkaProducer class, passing in the properties created in step 1.
3. Create a new instance of ProducerRecord, passing in the topic name to connect to, the key, and the message.
4. Send message by calling the method send() on the KafkaProducer instance, passing the ProducerRecord instance containing the message to be send.
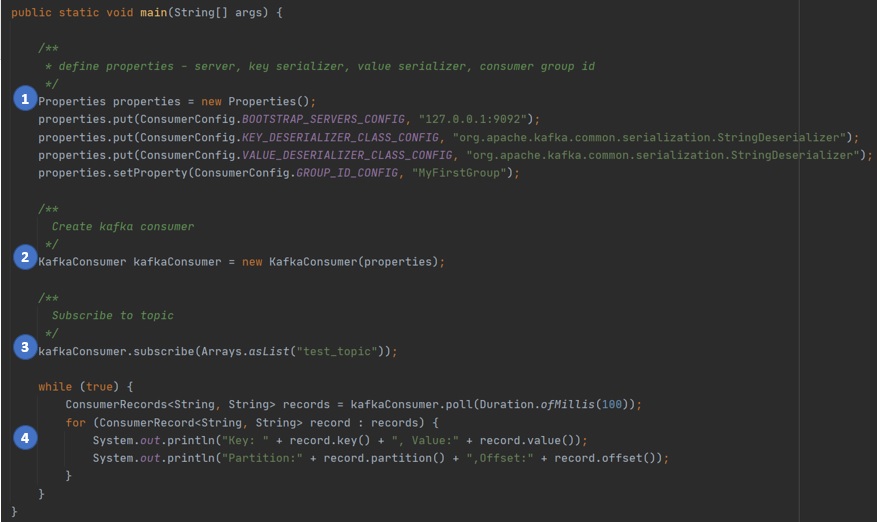
What are the keys steps in a Java program using Kafka Consumer API?
Key ConceptFollowing are the key steps in a Java program using Kafka Consumer API.
1. Define the properties required for the Kafka Consumer - the kafka broker to connect to, the key serializer type, the value serializer type, and the consumer group.
2. Create a new instance of KafkaConsumer class, passing in the properties created in step 1.
3. Subscribe to the topic to consume messages from, by calling the subscribe() method on the KafkaConsumer instance.
4. Listen to the kafka topic for new messages by calling the method poll() on KafkaConsumer instance, handling messages as instances of ConsumerRecord instances.
What security features does Kafka provide?
Key ConceptKafka provides the following security features.
1. Authentication of connections from clients (producers and consumers) to brokers, using SASL mechanisms.
2. Authentication of connections from brokers to ZooKeeper.
3. SSL Encryption of data transferred between clients and brokers, brokers and ZooKeeper, and between brokers.
4. Authorization of read and write operations by clients.
5. Pluggable authorization, with the ability to integrate with external authorization services.
What is Kafka Connect?
Key ConceptKafka Connect is a tool to stream data between Kafka and other systems scalably and reliably. Kafka Connect defines a common framework for Kafka connectors, can be deployed in distributed or standalone modes, and is ideal for bridging streaming and batch data systems.
What is Kafka Streams?
Key ConceptKafka streams is a client library for processing input data from input Kafka clusters, transforming the data, and sending the transformed data to output Kafka clusters.
What happens if a Kafka producer posts a message to a topic that does not exist?
Key ConceptIf a Kafka producer posts a message to a topic that does not exist, then Kafka platform creates that topic, with a default of 1 partition and 1 replication factor.
A warning is returned back by the producer saying that the topic does not exists, but the topic is created and the message is put into the topic, so the message is not lost.
Can you create a Kafka topic with replication factor greater than the number of brokers in the Kafka cluster?
Key ConceptNo, you cannot create a Kafka topic with a replication factor greater than the number of brokers in the Kafka cluster.
For example, if you only have 3 brokers in the cluster and you try to create a topic with a replication factor of 5, then you would see an error like..
Error while executing topic command : replication factor: 5 larger than available brokers: 3
How do you setup a multi-broker Kafka cluster?
FAQTo setup a multi-broker Kafka cluster you have to do the following 3 tasks.
1. Create a server.properties file for each of the servers you want in the cluster. At a minimum, you have to change the server id, port and log location for each of the property files.
2. Start the zookeeper server.
3. Start the servers in the cluster one by one using the property file of each server.
/** create separate property file for each server */
/** config/server-1.properties*/
broker.id=1
listeners=PLAINTEXT://:9093
log.dirs=/tmp/kafka-logs-1
/** config/server-2.properties*/
broker.id=2
listeners=PLAINTEXT://:9094
log.dirs=/tmp/kafka-logs-2
/** start zookeeper server */
> bin/zookeeper-server-start.sh config/zookeeper.properties
/** start kafka server 1*/
> bin/kafka-server-start.sh config/server-1.properties
/** start kafka server 2*/
> bin/kafka-server-start.sh config/server-2.properties
What is Hive?
FAQHive is a data warehousing framework based on Apache Hadoop which enables easy data summarization, ad-hoc queries and analytics on large volumes of Hadoop data.
Hive provides a SQL-like (HiveQL) interface to query data from Hadoop based databases and file systems.
Hive is suitable for batch and data warehousing tasks. It is not suitable for online transaction processing.
HiveQL queries are implicitly converted to MapReduce, Apache Tez and Spark jobs.
What are the key features of Hive?
FAQFollowing are the key features of Hive.
Hive provides a SQL-like interface to query data from Hadoop based databases and file systems. Hence Hive enables SQL based portability on Hadoop.
Hive supports different storage types such as HBase, text files etc.
What are the key architectural components of Hive?
FAQFollowing are the major components of a Hive architecture.
Metastore - Stores the metadata for each of the Hive tables.
Driver - Controller that receives the HiveQL statements.
Compiler - Compiles the HiveQL query to an execution plan.
Optimizer - Performs transformations on the execution plan.
Executor - Executes the tasks after compilation and execution.
UI - Command line interface to interact with Hive.
How do you create Hive tables using HiveQL?
FAQYou can create a Hive table using the DDL 'CREATE TABLE' statement.
CREATE TABLE employees (fname STRING, age INT)
How do you create Hive tables that can be partitioned using HiveQL?
FAQYou can create a Hive table that can be partitioned using the DDL 'CREATE TABLE... PARTITIONED BY... ' statement?
hive> CREATE TABLE employees (fname STRING, lname STRING, age INT) PARTITIONED BY (ds STRING);
How do you list tables in Hive?
FAQYou can list Hive tables using the DDL statement 'SHOW TABLES' statement?
SHOW TABLES
How do you list columns of a table in Hive?
FAQYou can list columns of a tables using the DDL statement 'DESCRIBE'?
DESCRIBE employees
How do you add new columns to a table in Hive?
FAQYou can add new columns to a table in Hive by using the DDL statement 'ALTER TABLE... ADD COLUMNS..'?
hive> ALTER TABLE employees ADD COLUMNS (lname STRING);
Where does Hive store the table metadata?
FAQBy default, Hive platform stores the table metadata in an embedded Derby database.
How do you load data from flat files into Hive?
FAQYou can load data from flat files into Hive by using the command 'LOAD DATA... INTO TABLE' command.
//Load from local files
hive> LOAD DATA LOCAL INPATH './files/employees.txt' OVERWRITE INTO TABLE employees;
//Load from Hadoop files
hive> LOAD DATA INPATH './files/employees.txt' OVERWRITE INTO TABLE employees;
How do you load data from flat files into different partitions of a Hive table?
FAQYou can load data from flat files into different partitions of Hive by using the command 'LOAD DATA... INTO TABLE... PARTITION...' command.
//Load from local files
hive> LOAD DATA LOCAL INPATH './files/employees.txt' OVERWRITE INTO TABLE employees PARTITION (ds='2008-08-15');
//Load from Hadoop files
hive> LOAD DATA INPATH './examples/files/employees.txt' OVERWRITE INTO TABLE employees PARTITION (ds='2008-08-15');
Apache Hue, which stands for 'Hadoop User Experience' is an open-source interactive tool for analyzing and visualizing Hadoop data.
What is Hue?
FAQHue, which stands for 'Hadoop User Exeprience', is an open-source web interface for analyzing data with Apache Hadoop. Hue is an analytics workbench designed for fast data discovery, intelligent query assistance, and seamless collaboration.
Hue focuses on SQL but also supports job submissions.
Hue is present in some major Hadoop distributions - CDH, HDP and MapR.
What are the data sources that Hue can connect to?
FAQHue primarily focuses on Apache Hive and Apache Impala.
In addition, Hue is also compatible with and supports the following sources.
- Any SQL database - Oracle, MySQL, SparkSQL, Apache Phoenix, Apache Presto, Apache Drill, Apache Kylin, PostgreSQL, Redshift, BigQuery etc.
- MapReduce
- Spark
- Pig
- Solr SQL
What are the key products included in Apache Hue?
FAQApache Hue consists of the following products.
Hue Query Editor - Hue Query editor is a user interface that provides capabilities and features which make querying data easy and more productive.
Hue Dashboard - Hue Dashboard is an interactive dashboard that provides capabilities for visualizing data quickly and easily.
Hue Scheduler - Hue scheduler lets you build workflows and then schedule them to run regularly and automatically.
What are the key capabilities provided in Hue Editor?
FAQApache Hue editor provides the following capabilities.
Importing and Managing Data - The Apache Hue editor provides a convenient user interface that assists in the management of metadata of the data sources. It provides drag & drop features, and table creation and import wizards to import data easily.
Querying Data - Apache Hue Editor provides a powerful autocomplete feature that supports language syntax and will highight any syntax or logical errors. It provides quick previews of datasets, highlights common columns and JOINs and provides recommendations for type optimized queries. Results can be exported to S3/HDFS/ADLS or downloaded as CSV/Excel.
What are the key capabilities provided in Hue Dashboard?
FAQApache Hue Dashboards provide an interactive way to explore and visualize data quickly and easily. No programming is required, the dashbaords can be created by drag and drop of widgets provided by Hue.
Hue Dashboards provide widgets for - Text, Timeline, Pie, Line, Bar, Map, Filters, Grid and HTML widgets that can be used for generating dynamic dashboards quickly and easily.
What are the key capabilities provided in Hue Scheduler?
FAQApache Hue provides scheduling features and capabilities that can be used to create workflows and schedule them to run automatically.
Apache Hue provides the Workflow editor which can be used to create, update, import and export workflows.
Apache Hue provides a monitoring interface that can be used to check the progress and status of jobs, start jobs, pause jobs etc.
How do you configure SQL data sources in Hue?
FAQYou configure SQL data sources in Apache Hue by using the configuration file 'hue.ini'. Some examples are listed below
[beeswax]
# Host where Hive Server is running.
hive_server_host=localhost
[impala]
# Host where Impala Server is running
server_host=localhost
What is Apache Oozie?
FAQApache Oozie is a workflow scheduler engine to manage and schedule Apache Hadoop jobs. Oozie supports different kinds of Hadoop jobs out of the box such as MapReduce jobs, Streaming jobs, Pig, Hive and Scoop. Oozie also supports system specific jobs such as shell scripts and Java jobs.
What kind of application is Oozie?
FAQOozie is a Java Web-Application that runs in a Java servlet-container.
What is Apache Oozie Workflow?
FAQApache Oozie Workflow is a collection of actions; which are Hadoop MapReduce jobs, Pig jobs etc. The actions are arranged in a control dependency DAG (Direct Acyclic Graph), which controls how and when an action can be run. Oozie workflow definitions are written in hPDL, a XML Process Definition Language.
What are the key components of Apache Oozie Workflow?
FAQApache Oozie Workflow contains control flow nodes and action nodes.
Control Flow Nodes - Control flow nodes are the mechanisms that define the beginning and end of the workflow (start, end, fail). In addition, control flow nodes also provide mechanism to control the execution path of the workflow (decision, fork and join)
Action NodesAction nodes are the mechanisms which triggers the execution of a computation/processing task. Oozie provides support for different types of Hadoop actions out of the box - Hadoop MapReduce, Hadoop file system, Pig etc. In addition Oozie also provides support for system specific jobs - SSH, HTTP, eMail etc.
What are the different states of an Apache Oozie Workflow job?
FAQAn Apache Oozie Workflow job can have the following states - PREP , RUNNING , SUSPENDED , SUCCEEDED , KILLED and FAILED.
Does Apache Oozie Workflow support cycles?
FAQApache Oozie Workflow does not support cycles. Apache Oozie WorkFlow definitions must be a strict DAG. At workflow application deployment time, if Oozie detects a cycle in the workflow definition then it fails the deployment.
What are the different control flow nodes supported by Apache Oozie workflows that start and end the workflow?
FAQApache Oozie workflow supports the following control flow nodes that start or end the workflow execution.
Start Control Node - The start node is the first node that a Oozie workflow job transitions to and is the entry point for a workflow job. Every Apache Oozie workflow definition must have one start node.
End Control Node - The end node is last node that a Oozie workflow job transitions to and it indicates that the workflow job has completed successfully. When a workflow job reaches the end node it finishes successfully and the job status changes to SUCCEEDED. Every Apache Oozie workflow definition must have one end node.
Kill Control Node - The kill node allows a workflow job to kill itself. When a workflow job reaches the kill node it finishes in error and the status of the job changes to KILLED.
What are the different control flow nodes supported by Apache Oozie workflows that control the workflow execution path?
FAQApache Oozie workflow supports the following control flow nodes that control the execution path of the workflow.
Decision Control Node - The decision control node is like a switch-case statement, which enables a workflow to make a selection on the execution path to follow.
Fork and Join Control Node - The fork and join control nodes are used in pairs and work as follows. The fork node splits a single path of execution into multiple concurrent paths of execution. The join node waits until every concurrent execution path of the corresponding fork node arrives to it.
What are the different Action nodes supported by Apache Oozie workflow?
FAQApache Oozie supports the following action nodes which trigger the execution of computation and processing tasks.
Map-Reduce Action - The map-reduce action node starts a Hadoop Map-Reduce job from a Oozie workflow.
Pig Action - The pig action node starts a Pig job from a Oozie workflow.
FS (HDFS) Action - The FS action node enables an Oozie workflow to manipulate HDFS files and directories. FS action nodes support the commands - move , delete , mkdir , chmod , touchz and chgrp .
SSH Action -
Sub-workflow Action -
Java Action - The java action node executes the public static void main(String[] args) method of the specified main Java class form a Oozie workflow.
Describe the life-cycle of Apache Oozie workflow job?
FAQThe Apache Oozie workflow job transitions through the following states.
PREP- An Oozie workflow job is in the PREP state when it is first created. In this state the workflow job is defined but is not running.
RUNNING - An Oozie workflow transitions to the RUNNING state when it is started. The workflow remains in RUNNING state while the workflow does not reach its end state, ends in error or it is suspended.
SUSPENDED - An Oozie workflow job transitions to SUSPENDED state if it is suspended. The workflow will remain in suspended state until it is resumed or it is killed.
SUCCEEDED - A RUNNING Oozie job transitions to the SUCCEEDED state when it reaches the end node.
KILLED - A CREATED, RUNNING or SUSPENDED workflow job transitions to a KILLED state when the workflow job is killed by an administrator.
FAILED - A RUNNING Oozie job transitions to a FAILED state when the workflow job fails with an unexpected error.
What is Apache Sqoop?
FAQApache Sqoop is a tool used for transferring data between Apache Hadoop clusters and relational databases.
Sqoop was originally developed by Cloudera. The name 'Sqoop' is a short form for 'SQL-to-Hadoop'.
Sqoop can import full or partial tables from a SQL database into HDFS in a variety of formats. Sqoop can also export data from HDFS to a SQL database.
Describe the architecture of Apache Sqoop?
FAQApache Sqoop uses Hadoop MapReduce to import data from SQL database to HDFS.
Sqoop orchestrates the following three tasks to import data from a SQL database to HDFS.
1. Examines the table details and identifies the number of records that will be imported.
2. Creates and submits MapReduce jobs to Hadoop cluster.
3. Fetch records from the SQL database and mports this data to HDFS.
What is the basic command-line syntax for using Apache Sqoop?
FAQApache Sqoop is a command-line utility that has various commands to import data, export data, list data etc. These commands are called tools in Sqoop. Following is the basic command-line syntax for using Apache Scoop.
$ sqoop tool-name [tool-options]
Describe the process by which Apache Sqoop imports data from a relational database to HDFS?
FAQHadoop follows the following process to import data from a relational database to HDFS.
1. Sqoop examines the relational database table from which the data has to be imported, and if possible determines the primary key.
2. Sqoop runs a boundary query on the table to determine how many data records will be imported.
3. Sqoop divides the number of records by the number of mappers, and uses this to configure the mapper tasks such that the load is distributed equally among the mappers.
How do you connect to a relational database using Sqoop?
FAQYou connect to a relational database with Sqoop using the '--connect' command. For example, below code connects to a mysql database.
$ sqoop --connect jdbc:mysql://myhostname/interviewgrid
--username myusername --password mypassword
How do you import data into a specific directory instead of the default HDFS home directory?
FAQYou can import the data from a relational database into a specific directory using the option '--warehouse-dir.
$ sqoop import-all-tables
--connect jdbc:mysql://myhostname/interviewgrid
--username myusername --password mypassword
--warehouse-dir /interviewgrid
How do you import data from a single table 'customers' into HDFS directory 'customerdata'?
FAQYou can import the data from a single table using the tool or command 'import --table'. You can use the option '--warehouse-dir' to import the data into 'customerdata' HDFS directory.
$ sqoop import --table customers
--connect jdbc:mysql://myhostname/interviewgrid
--username myusername --password mypassword
--warehouse-dir /customerdata
How do you import data from specific columns of a relational database table into HDFS?
FAQYou can import data from specific columns of a relational database table into HDFS using the option '--columns'.
Below code snipped imports the data from columns 'first_name' and 'last-name' into HDFS.
$ sqoop import --table customers
--connect jdbc:mysql://myhostname/interviewgrid
--username myusername --password mypassword
--columns 'first_name, last_name'
--warehouse-dir /interviewgrid
How do you specify a delimiter for the data imported by Sqoop?
FAQBy default, Sqoop imports data as comma delimited text files. You can specify Sqoop to use a different delimiter by using the option '--fields-terminated-by'.
Below code snippet imports the data as tab delimited text files.
$ sqoop import --table customers
--connect jdbc:mysql://myhostname/interviewgrid
--username myusername --password mypassword
--columns 'first_name, last_name'
--warehouse-dir /interviewgrid
--fields-terminated-by ' '
How do you compress the data imported by Sqoop?
FAQYou can compress the data imported by Sqoop by using the command option '--compression-codec'.
$ sqoop import --table customers
--connect jdbc:mysql://myhostname/interviewgrid
--username myusername --password mypassword
--compression-codec org.apache.hadoop.io.compress.SnappyCodec
How do you specify Sqoop to import data in other formats other than text?
FAQIn addition to text files, Sqoop supports importing data as Parquet files and Avro files.
You can specify Sqoop to import data as as Parquet files and Avro files by using the option '--as-parquetfile'
$ sqoop import --table customers
--connect jdbc:mysql://myhostname/interviewgrid
--username myusername --password mypassword
--as-parquetfile
How do you export data from HDFS to a relational database using Sqoop?
FAQSimilar to 'import' tool, Sqoop provides the 'export' tool that pushes data from HDFS to a relational database.
$ sqoop export
--connect jdbc:mysql://myhostname/interviewgrid
--username myusername --password mypassword
--export-dir /interviewgrid/output
--update-mode allowinsert
--table customers
