System design interview questions have become a standard part of software engineering interview process, especialy for senior level roles. Most candidates struggle with system design interview questions; either because they do not have the experience in designing large-scale systems, or because they have not prepared for the open-ended and unstructured nature of such questions.
There are many ways to prepare for and answer a system design interview question. Below is one way that uses a 7 step approach to solve system design interview questions.
Step 1 - Clarify Requirements and Determine Scope
- Who are users of the system?
- People?
- Systems?
- Processes?
- What features and functionality are in scope?
- What actions are performed on the system?
- Writes?
- Gets?
- Updates?
- Deletes?
- Does the system have a UI? Is UI design in scope for this interview?
Step 2 - Estimate for Scale (Back of the Envelope Estimations)
Ask questions to interviewer to understand the requirements and scope for the interview. Below are some of the questions for most systems.
- Estimate scale
- Number of requests per second
- Number of Read vs Write requests.
- Estimate storage
- Estimate size of write request
- Estimated storage requirement per year
- Estimate bandwidth
- Payload size of read and write requests
- Bandwidth requirement per second
Step 3 - High Level Design
Include following components if applicable
- Client
- DNS Server
- DNS Server
- UI/Web layer (react.js, angular.js, backbone.js, etc.)
- Service/API Layer (app servers, micro services, etc.)
- Data layer (database, image storage, file server, etc.)
- Async/off-line processing (messaging queue, kafka, .etc)
Step 4 - High Level Design for Scale
Sketch High Level Design For Scale
Include following components if applicable
- Load-balancers
- Caching
- Data partitioning
- Data replication
Step 5 - Data Model (Optional)
- Define entities
- Define interaction between entities
- SQl, NoSQL or Both?
Step 6 - Define the System Interface Definition (optional)
- Services
- API Endpoints for each service
Step 7 - Deep Dive (optional)
Deep dive into one or more of key components
- Any specific algoriths to use
- Address any bottlenecks
System design involves identifying the 'components' and laying out the interaction between these components, based on the functional and non-functional requirements given for a specific system to be designed.
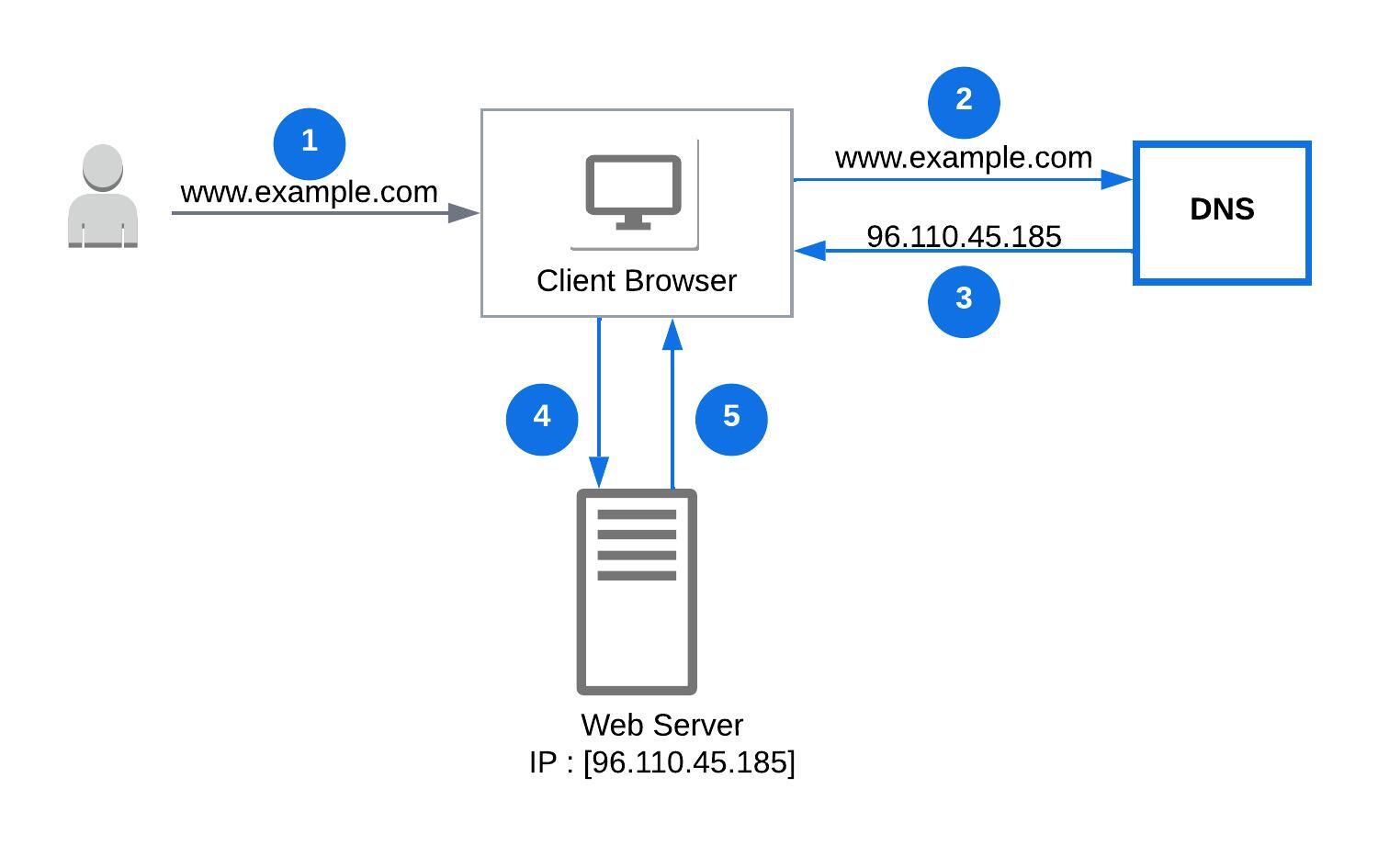
Domain Name System (DNS)
Domain Name System (DNS) is a distributed system that maintains mapping of human readable domain names such as 'www.google.com' to their IP addresses.
When a user enters a domain name on the browser URL the request is sent to a DNS server provided by the user's ISP. The DNS server checks if it has the IP address for the domain, else it sends a lookup request to other DNS servers.
The DNS server then returns the IP address back to the browser, which receives the web page by contacting the server by it IP address.
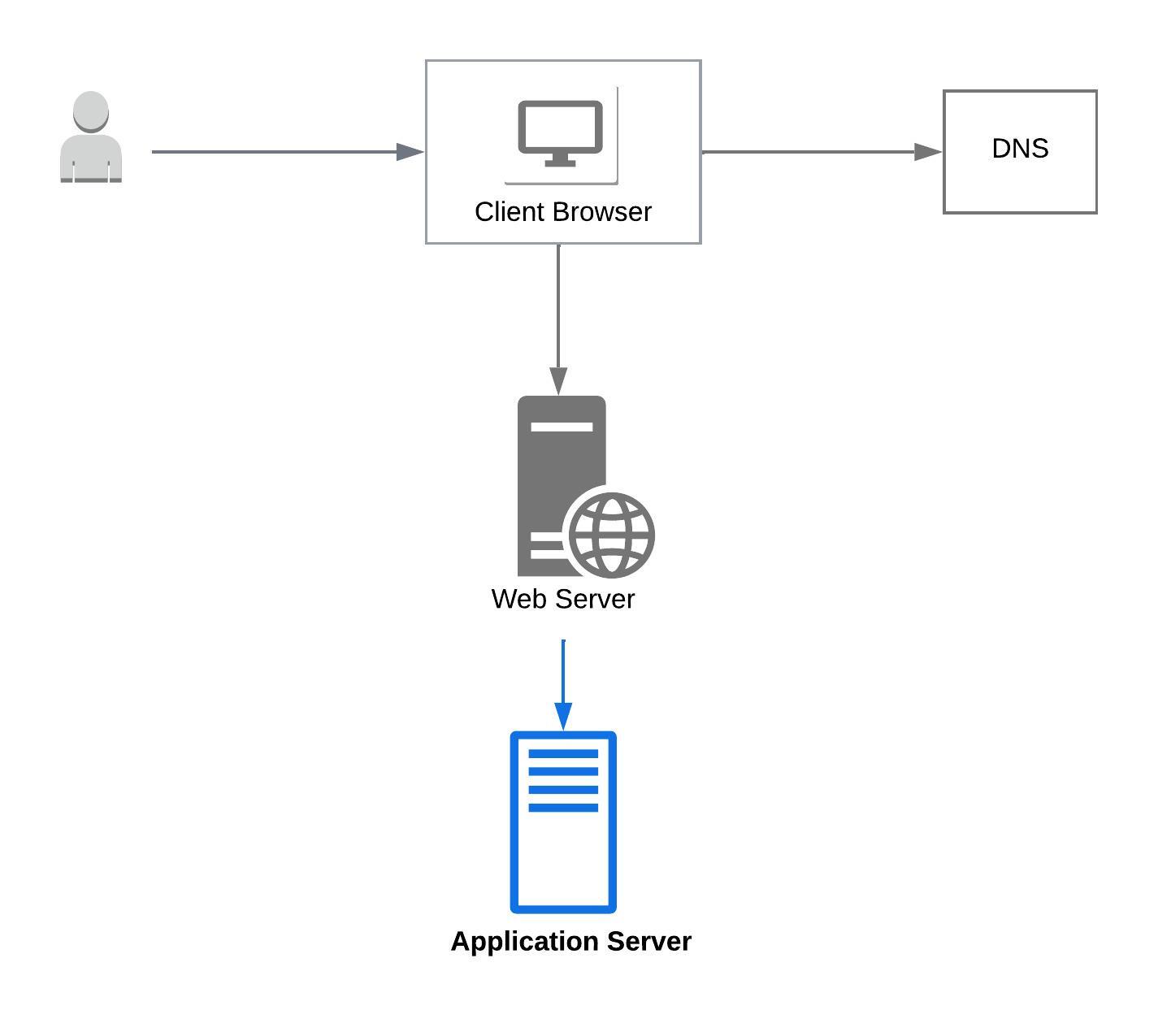
Web Servers
Web servers serve static content such as HTML pages, images, videos, and files to client browser.
Web servers support server side scripting, log incoming requests, and usually support HTTP protocol.
Web servers interact with application servers, which has application and business logic, to serve more dynamic and interactive content to requests.

Application Servers
Application servers have more complex business logic to process data and return dynamic data to web servers, which in turn returns it to the client browsers.
To return dynamic data application servers interact and pull data from various sources such as databases, APIs, message queues etc.
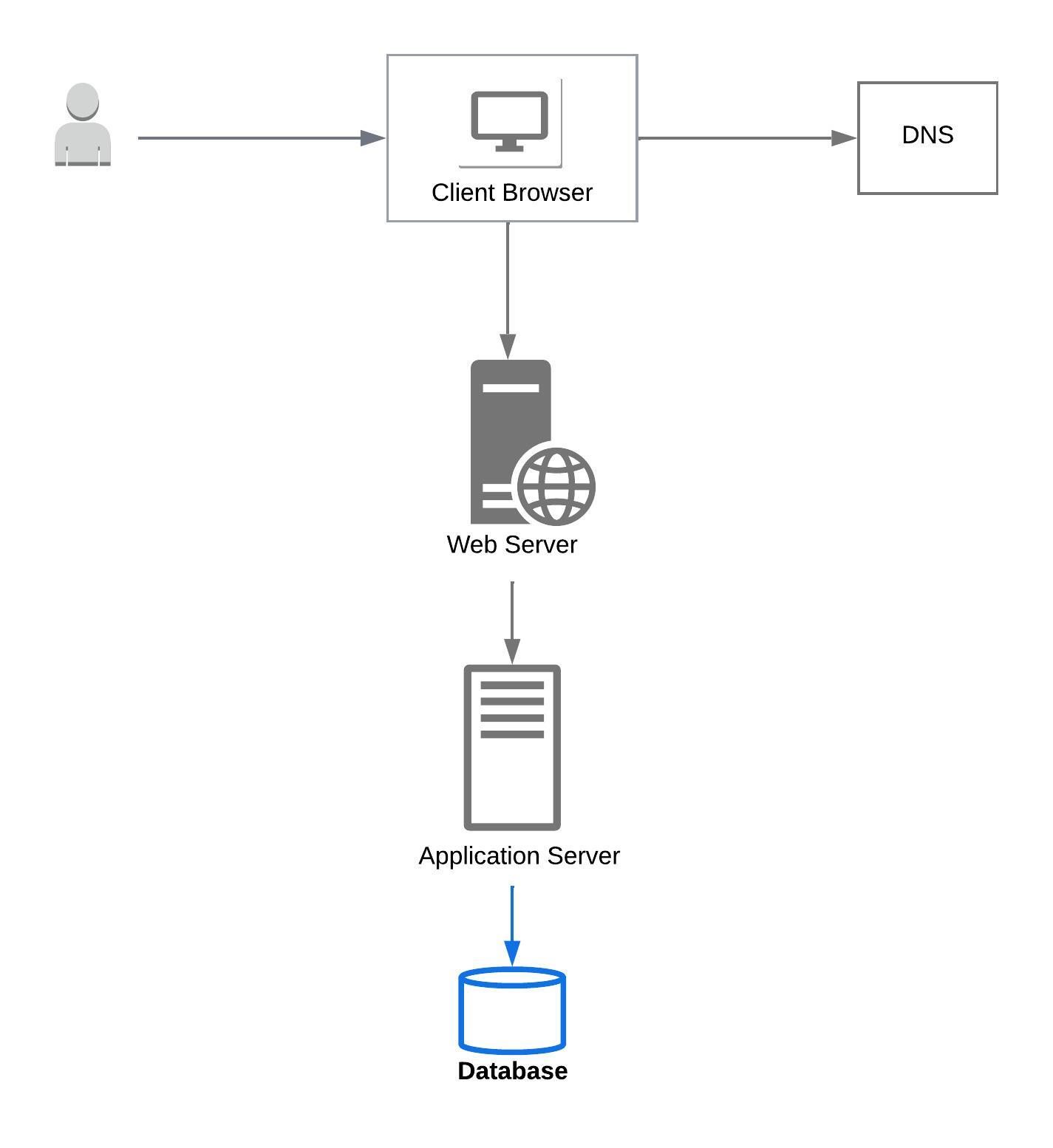
Databases (SQL, NOSQL)
Databases store data that can be retrieved, modified, or deleted using processes provided by the database.
Databases can be relational (SQL) or Non-relational (NoSQL). NoSQL databases can be key-value store, document store, wide column store, or a graph database.
Each database type has advantages and dis-advantages and the selection of the database depends on the use case and the data that we need to store.
Blob Storage
Blob storage is typically used to store large unstructured data such as multimedia files, binary executables etc.

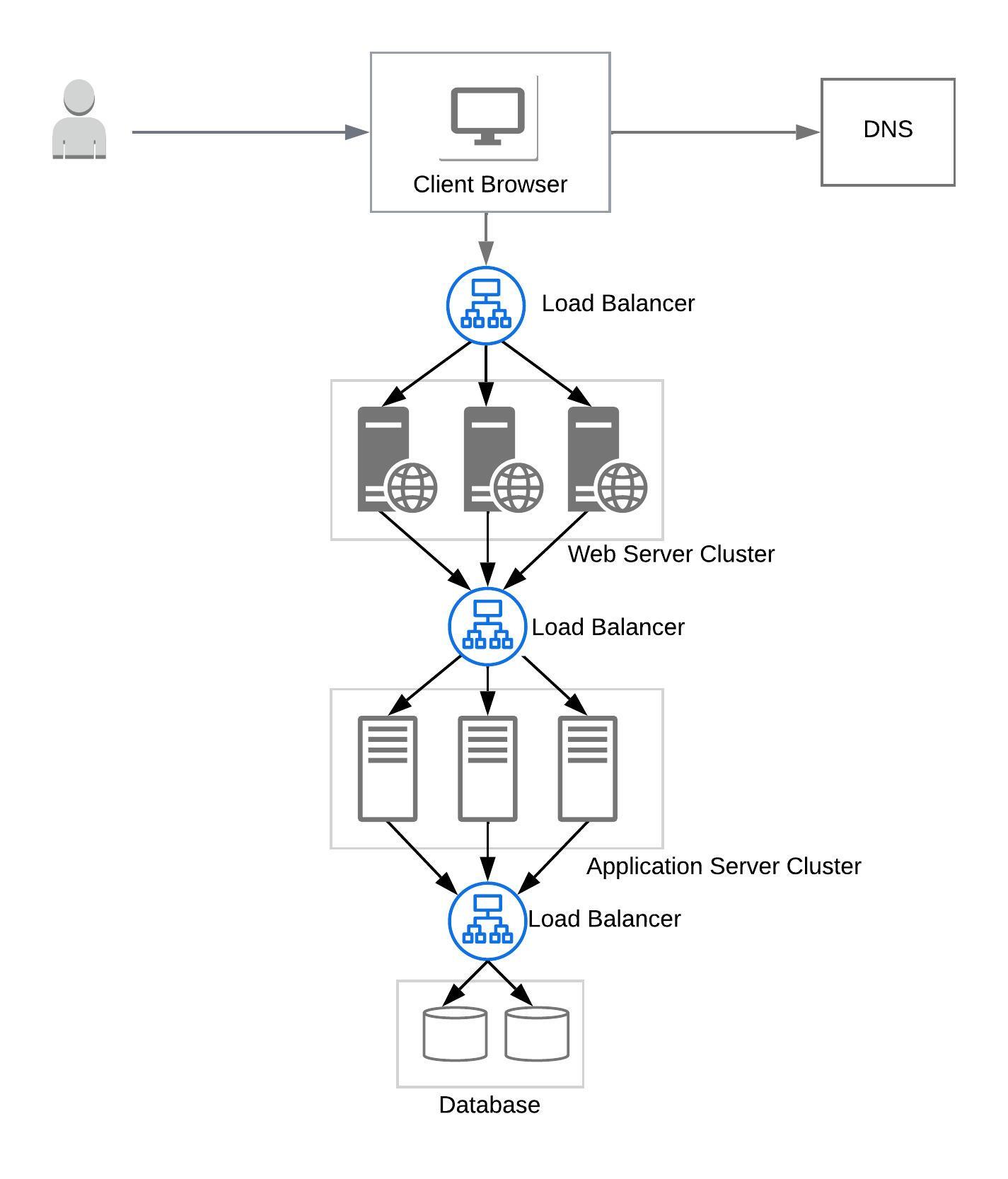
Load Balancers
A load balancer distributes network traffic across a cluster of servers. This ensures that no single server is over-loaded; hence improving the responsiveness of an application, and also improving the availability of the application.
In a distributed application multiple load balancers are commonly put between different layers -
- Between the client and web servers
- Between the web servers and application servers
- Between the application servers and database servers.
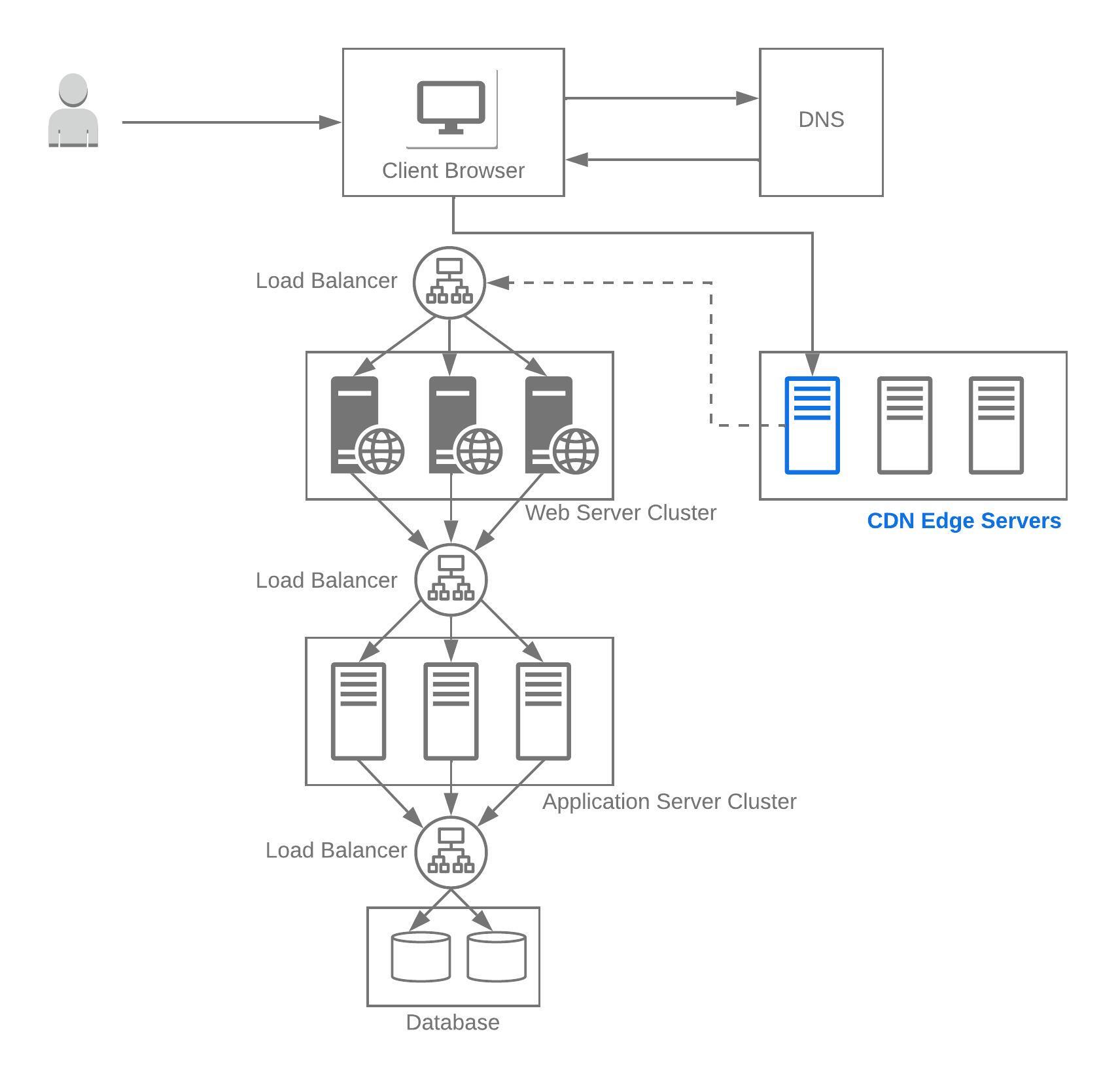
Content Delivery Network (CDN)
Content Delivery Network (CDN) is a globally distributed network of servers that serve content from locations closest to the users.
Traditionally CDNs served static content files and pre-generated files such as HTML, CSS, JS, image and images. CDNs have evolved since to now serve dynamic content as well, including rich media.
Content served from CDN significantly improves the performance by reducing latency, since the content is served from servers closest to the users. In addition the load on the servers is also reduced since they do not have to serve content that is served from CDN.
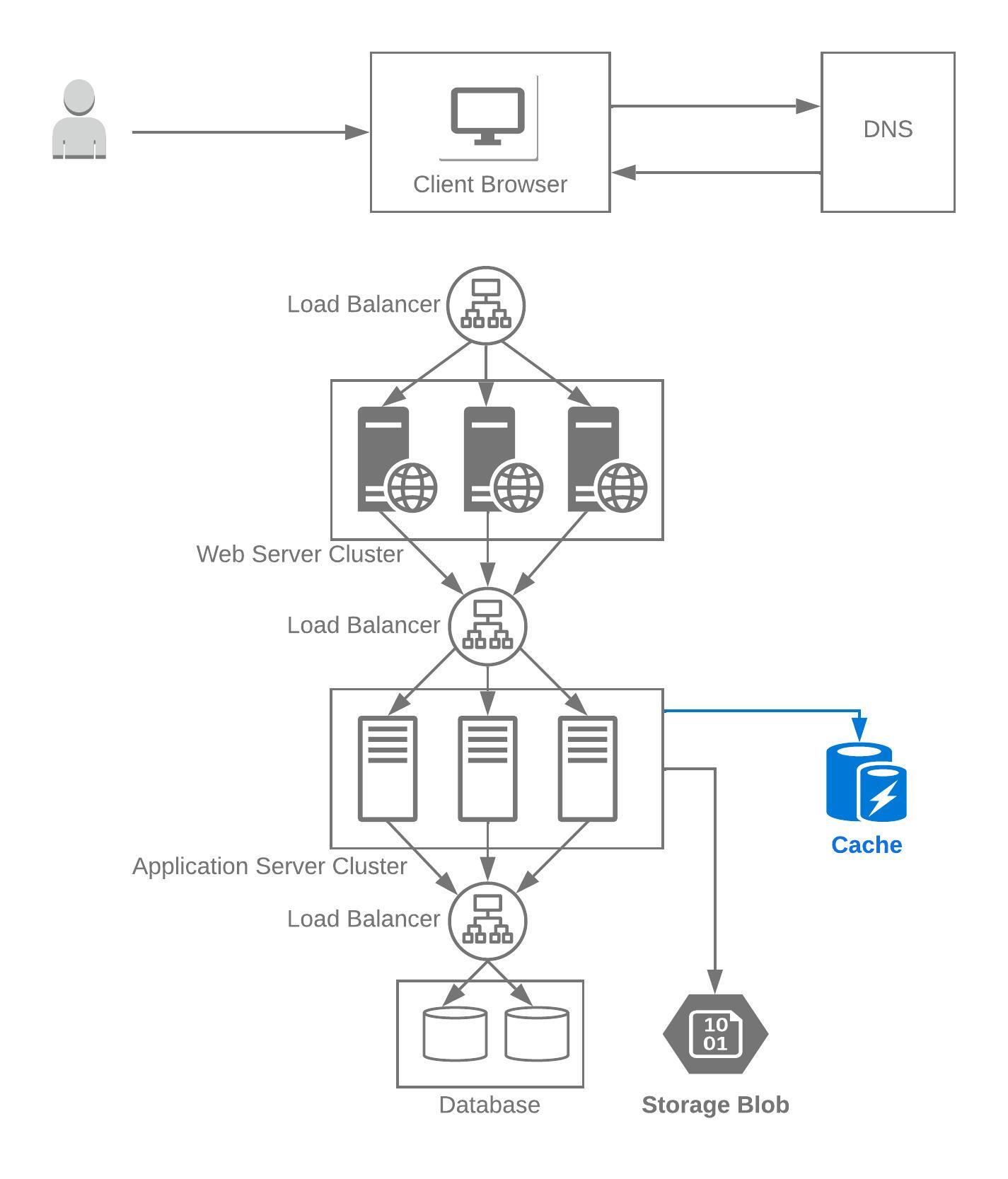
Caching
Caching is the mechanism of storing data in a temporary storage location, either in memory or on disc, so that request to the data can be served faster.
Caching improves performance by decreasing page load times, and reduces the load on servers and databases.
In a typical caching model, when a new client request for a resource comes in, a lookup is done on the temporary storage to see if a similar request came in earlier. If a similar request is found then the previous result is returned with out hitting the server or database. If a similar request is not found, then the client request is send to the server or database to fetch the result, the result is updated in the temporary storage, and the result is returned back to the client.
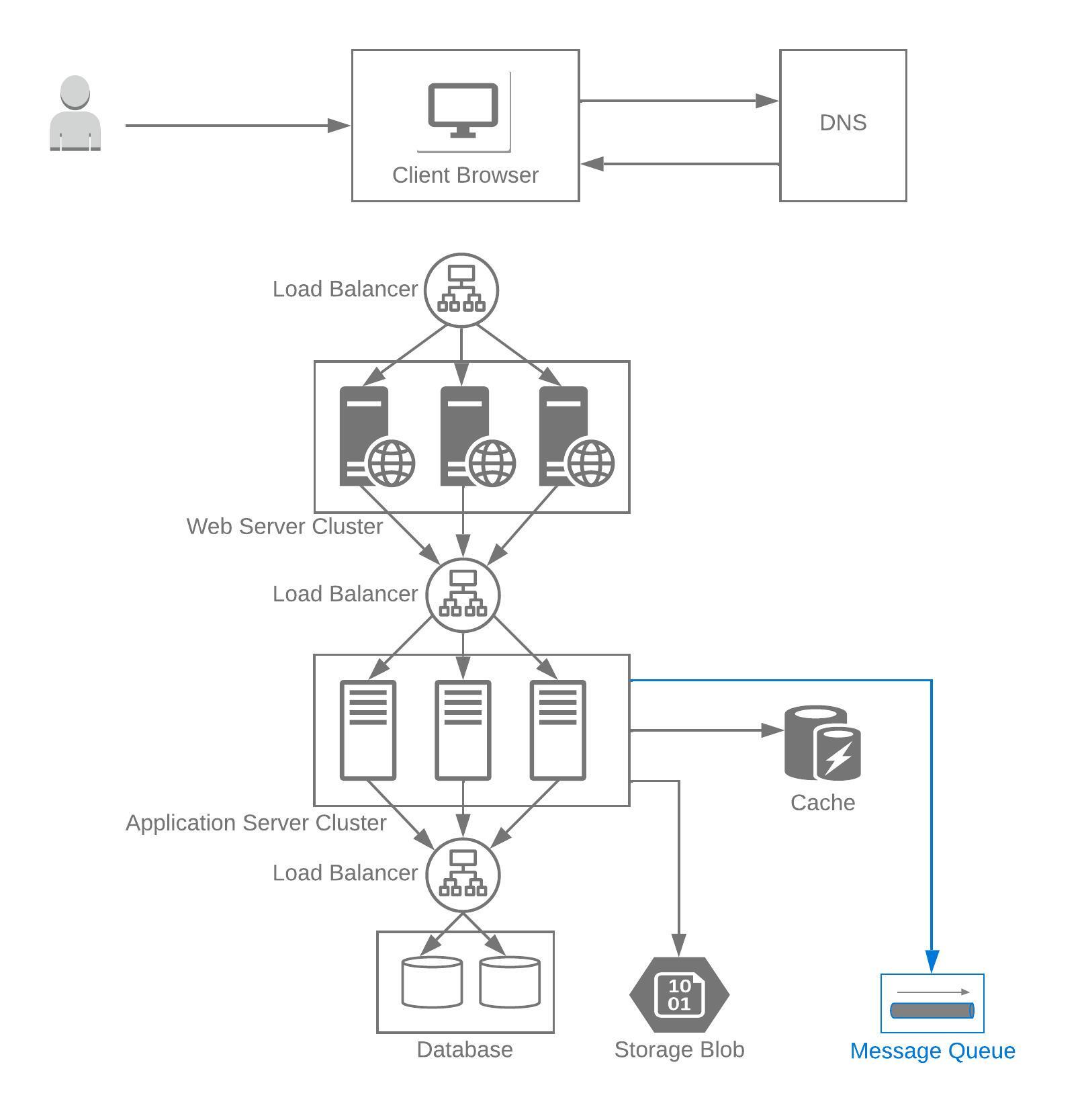
Asynchronous processors
Asynchronous workflows help decouple processes, reduce request times for expensive operations, and can complete time-consuming work in advance.
Asynchronous workflows can be implemented via message queues which receive and hold messages in an asynchronous workflow. Producers post messages to the queue and consumers consume messages from the queues.
Batch Processors
Batch Processors
Rate Limiters
A rate limiter limits the number of requests that a service fulfills. It throttles or blocks requests if they exceed the limit.
A rate limiter protects services against attacks such as denial-of-service (DOS) attacks and brute-force password attempts.
Rate limiter also acts as a defensive layer for services to prevent excessive usage, whether intended or unintended.
Distributed Search
Distributed Search
